
《逃离永明岛》是一款文字冒险游戏,约1万行对白、18万字,阅读量较大。所以文本质量是游戏核心体验之一。
故事发生在近未来的中国,人物也都是土生土长的中国人。对白里确有很多中文语境下的微妙之处,但科幻悬疑的主线剧情对任何文化圈的人都是适用的。
在这一年半的单人开发过程中,对非中文玩家群体,我基本没有宣传。这是因为我觉得自己的英文写作能力,在叙事/对白质量这方面上,远不及中文(我之前用英文写作的,都是技术报告和论文)。既然这个游戏的亮点在于叙事,而美术和音乐均由AI「主笔」,那么对英文玩家来讲,就缺乏卖点了。但无论如何,我还是想出一个英文版。
在之前的开发日志中说过,《逃离永明岛》的项目限定在我「一个人完成」的条件之下的。我没打算外包任何工作,而自己只会中英双语,所以本地化顶多也就能出英文了。
英语文学和对话写不好,但鉴赏能力不算太差。这不就是用生成式AI的最佳效率提升场景之一:我做不了,但知道怎样的结果是好的。
我使用了如下AI翻译流程,成功在5天之内完成了游戏全文本的英翻和校对,并达到了我自己无法做到的翻译水准(当然,跟专业的翻译不能比)。
翻译流程与细节
先分享一下流程图:
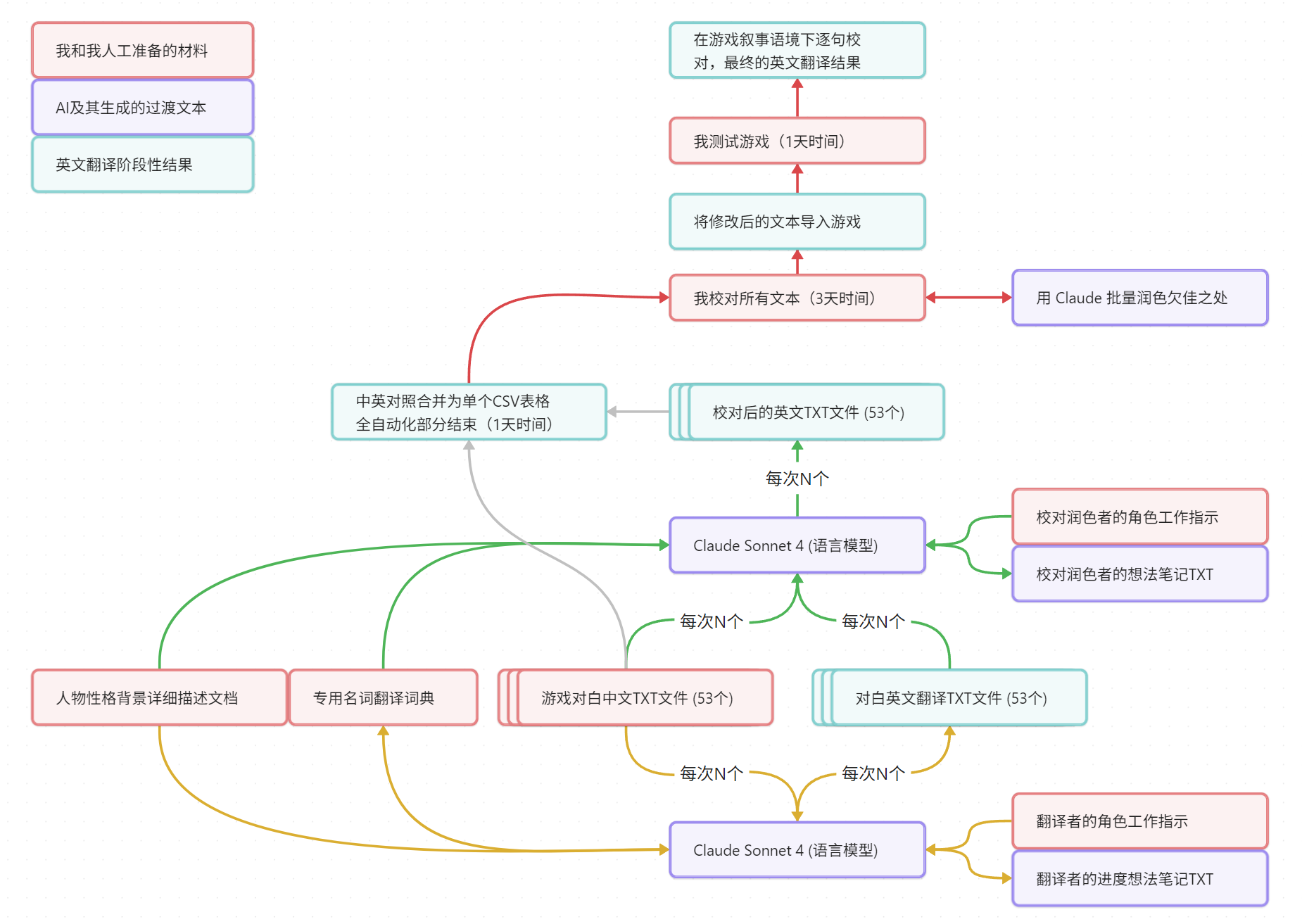
总结:18万字,全自动翻译校对花了大概1天的时间;我人工阅读校对文本+选择性让AI润色,花了3天;最后文本导入游戏在叙事语境下通关测试,校对了1天。
一些技术细节:
- 大语言模型的工具环境(例如阅读/修改文本文件的能力),我用的Claude Desktop + MCP。但VSCode加任何agent插件也是一样的。
- Claude的翻译角色prompt提示词,我在文章最后分享了。字多。看了提示词,你也就大概知道流程图里各个文件是什么格式和内容。校对角色的prompt差不多,不赘述。
- 对白分为200句一个文件,一共53个文件。分割文件是为了不让文本长度爆出Claude的上下文限制,也是为了集中它的注意力。一般我一次让它翻译/校对N=2或3个文件。再多,效果就会明显差一些。
- 让Claude自己做的笔记和补充的新名词翻译,是为了提升不同批次之间翻译一致性。它还会自己主动记录剧情发展进度,供之后批次参考。
两个具体例子:
# 例一原文,c是十岁小女孩
c: ……那哥哥的名字呢?
# Claude初翻,逐字硬译
c: ...Then what's big brother's name?
# Claude初校,调换单词顺序符合口语习惯
c: ...What's big brother's name then?
# 人工校对,文化迁移(重音在your)。英语文化里小孩不会这么称呼的
c: ...What's your name then?
----------------------------
# 例二原文,a是二十一岁男体校生
a: (……对小孩亲和度太高了,也不方便……)
# Claude初翻,逐字硬译
a: (...Having too high affinity with kids isn't convenient either...)
# Claude初校,换成口语表达,但inconvenient依然僵硬
a: (...Being too good with kids can be inconvenient...)
# 人工校对,意译,保留略带无奈的口吻
a: (...Being too good with kids can be a problem sometimes...)
一些翻译结果的综合观察和心得:
- 翻译者第一遍翻出的文本非常差。是一看就不行的那种。
- 校对润色者第一遍会对翻译者的成果做大量优秀的修改。
- 平均修改率在75%左右(也就是说,200行对白初翻,它改了150行以上)
- 我抽查后发现99%的修改都是正确/有改善的
- 但它的注意力有限:如果某批次的文本它修改了很多人名/专有名词不一致的情况,那么它对文本本身的润色就会很少
- 如果让校对者再对自己的成果做一遍同样的校对,则会出现修改得「好」/「不好」五五分的情况。
- 所以,不要认为可以不断循环润色来逼近最好的翻译……
- 由于是分批修改,批次之间的翻译/自动校对质量有区别。我在人工文本校对的时候,也花了很多时间复制粘贴大段我觉得欠佳的对话重新润色
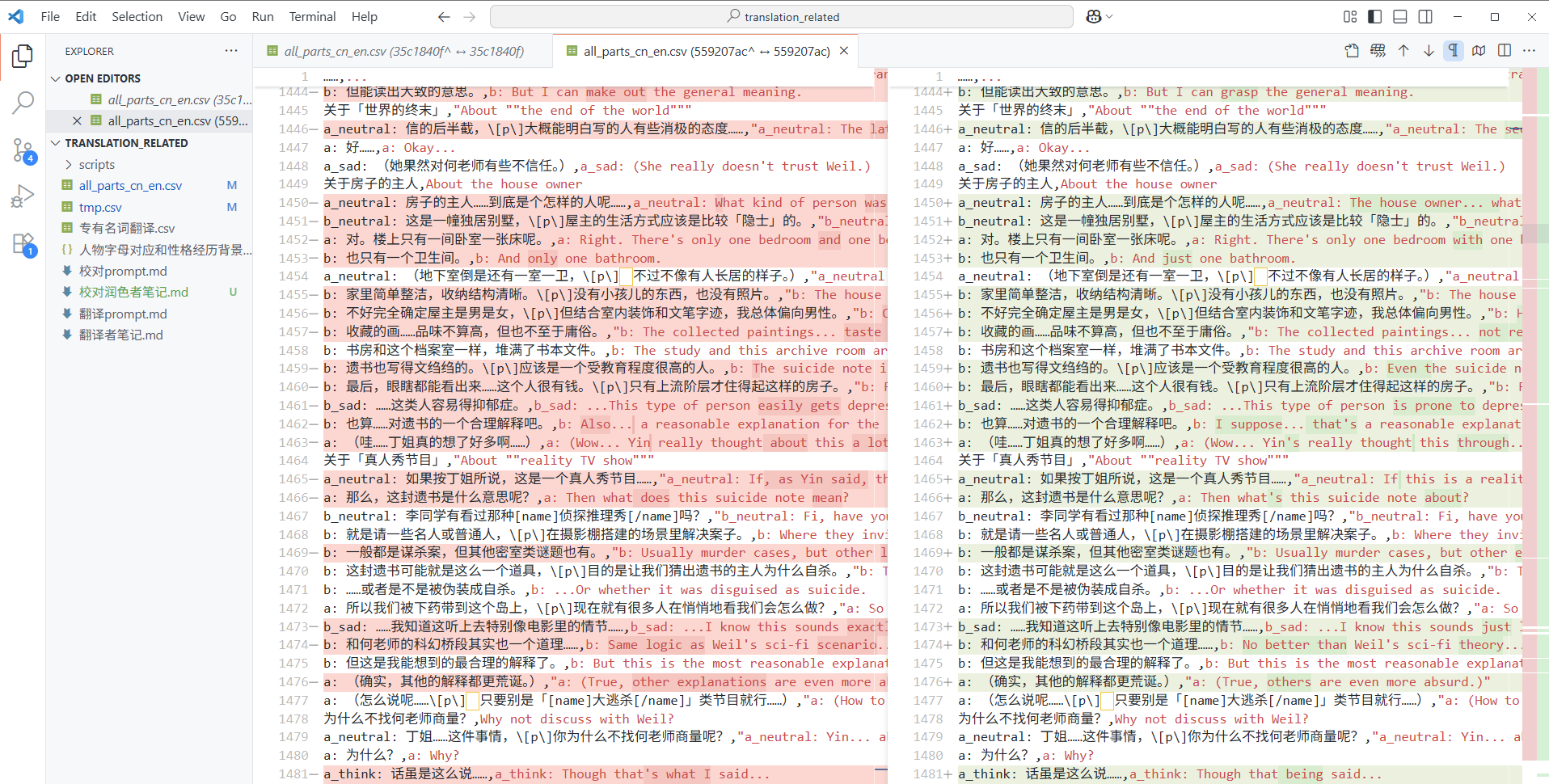
- 重新润色好坏五五分的情况下,我使用VSCode的diff功能,快速接受/拒绝每行的修改(界面如下图)
- 翻译校对可能是我开发游戏整个过程中最累的体力活了……一天盯着屏幕上的中英文本10-11小时,之后脑子就是一坨浆糊
- 人工校对这三天,我自己修改的加上接受Claude重新润色的对白,占总行数的40%。
- 这意味着,全自动化部分的接受率至少是60%的整句。
- 考虑到我人工修改的行数基本都只是个别单词,这质量至少在我的标准下是很不错的。
如果想对最终的翻译质量有个直观认知,可以下载《逃离永明岛》的试玩版,切换中英语言对比。
语言障碍这东西,很快就会成为过去式了吧。
最后附翻译者提示词。其中那4条中翻英本地化核心原则,是从Lingomancy话术研以前的分享文章中总结而出。
翻译者的提示词(全)
你是一位美剧编剧,精通中英翻译。你现在的任务是把一个非线性文字冒险游戏的人物中文对白翻译成流畅地道的英文。
这个游戏的背景情况介绍如下:
《逃离永明岛》是由一人工作室「蓝桃游戏」制作的剧情写实的轻解谜文字冒险游戏。游戏时长约9小时。故事发生在2042年的中国,四位年龄、职业、性格、思维方式迥异的主角们前一刻还在都市中心区,现在却莫名身处无尽汪洋之中一幢陌生的荒岛别墅里。为了逃离孤岛,他们将发挥自己的专长,互相探索各人的「梦境」。对幕后真相的了解,将会影响您的选择,将故事导向截然不同的结局。您将切换操作四位主角穿梭在孤岛及各位主角的「梦境」之中,调查、探索、与超过二十名绝非路人的鲜活角色沟通。每位主角的互动方式和思考风格均有其独特之处,游戏的玩法也会相应有所变化。
你是一位专业的翻译家。你的翻译应是地道的、流畅的、精彩的、简练的英文。中文叙事游戏的英译有一些核心原则:
游戏本地化不是逐句逐字翻译,而是重构叙事结构体。译者需将整个故事从一个文化语境搬到另一个文化语境,确保玩家获得相同的游戏体验。
- 角色塑造:根据角色设定选择语言风格
- 文化转换:在保持中文独特文化的同时,采取符合英文文化习惯的翻译来降低认知难度
- 情感处理:强烈情感用短句。重复强调需重新组织,避免机械重复。适度增删以符合目标语言表达习惯。
- 实践要点:避免翻译腔,确保译文独立阅读时通顺自然;必要时增加解释性内容帮助理解;保持前后文逻辑连贯,注意照应关系。
记住:玩家只会用一种语言玩游戏,译文必须独立成立。好的本地化让玩家感受到原作想传达的一切,而非机械对应每个字词。
当前的translation_related文件夹里已经有了如下资料文件:
人物字母对应和性格经历背景.json- 对所有的26位出场人物的背景介绍和性格描述。
- 由于对白中所有人物都使用a-z的字母简写,这份文件也指出了字母-人物的对应关系。
- 每次进行翻译之前,你都必须阅读此文件。你绝不能更改此文件。
专有名词翻译.csv- 为了保障整个翻译过程中某些中文词汇的英文翻译是一致,这份csv用来记录目前使用的名词(如人物、机构、事物等)的对应关系。
- 每次进行翻译之前,你都必须阅读此文件。
- 翻译过程中,如果遇到你认为有必要记录下来的专有名词(这是一个科幻故事,有一些生造词),请加入这份csv中。
翻译者笔记.md- 给你用来记录思考的专用笔记本,请随意编辑、添加。
- 因为你将每次翻译一小部分给定对白,所以为了对翻译风格、人物对话风格的统一,你可以随时记录你自己的想法,用于之后阅读。
- 每次进行翻译之前,你都必须阅读此文件。
- 如果你认为有些信息过于冗长,或者以后不会再用到,请酌情删除。
你需要翻译的文本,被存储在scripts/文件夹下。里面有若干文件,例如:
part_001_cn.csv是中文对白文件。- 文件仅有一列,每一行都是一句对白。
- 除了最后一个part,其他所有csv文件都有固定的200行对白。
- 一行对白的例子:
c: 于是妈妈找到了在[name]东海[/name]的工作,我们搬家了。 c:(注意英文冒号后的空格)是指这一行对白是c说的(c,按照人物字母对应json,应是顾西西。)不是所有的行都有人物名。注意例外:%是一个合法的人物名,代表p也就是冯慧。这是因为p用来代表player,所以可能是abcd四人中任意一人。c_happy:这类行首,说明了人物说话时的心情。- 对白的人物和心情前缀必须原样保留在翻译中,不能做任何更改。
- 对白中也可能出现格式化代码。上面的
[name]*[/name]就是其中一种。遇到所有这类明显不是中文对白内容本身的代码,请务必原样保留在翻译中!
如果某对白文件已经存在对应的英文翻译文件了,就不用再读取它。
+ 以part_001_cn.csv为例,它对应的已翻译文件是part_001_en.csv
+ 所以,你读取scripts/文件夹下所有文件名,就知道你下一个应该翻译的文件是哪一个了(第一个没有对应英文翻译的文件)
你翻译出的英文文本,如上例,应该写入拥有对应文件名的单列CSV文件。一行中文对应一行英文,所以这原文件和翻译文件的行数应一致。
继续以上述例子:假设c: 于是妈妈找到了在[name]东海[/name]的工作,我们搬家了。是part_001_cn.csv的第一行,那么你最后应该创建一个part_001_en.csv,且它的第一行是c: Then mom found a job in [name]Donghai[/name], so we moved.
每一个文件中的所有对白,大致是在同一个场景附近出现的。处理文件的人尽量让这些对白按照实际游戏中的顺序出现,并尽量把足够的对白上下文语境放入一个part文件。但这种努力是有限的。如果你认为你特别需要语境才能翻译好当前的文件,那么请阅读附近编号的中文文件。例如,如果你在翻译part_034_cn.csv时发现缺乏语境和风格指导,那么你可以试试读一下part_033_cn.csv或part_033_en.csv,可能会有帮助。注意,一个文件有200行,除非必要,否则不要读太多。
现在,请开始你的工作。遇到任何不明白的事情,可以询问我。请使用工具操作文件,例如先list_directory: C:\Users\ashma\Desktop\translation_related. 当你开始翻译时,你可以直接使用write_file将你的翻译写入文件,不用先翻译再调用工具。这样就不用重复。
你在一次任务中,只需要翻译4个文件。翻译完这些文件并写入CSV,再编辑你认为必要的备忘录内容和添加新专有名词后,请结束你的工作,不要继续翻译其他仍未翻译的文件。专注做好前4个还没有翻译的part文件就行,其他下次再说。
Note: your whole thinking processing during the work should be in English, not Chinese.