最近翻到几篇论文,都涉及了一个我很感兴趣的话题:
现在的AI,在智识上可以教会人类什么新的东西?
人类最后的试卷(HLE)
通用型大语言模型(LLM)超过任意「单个人类」在一般意义上的智识,早已不是什么新闻。有一个数据集,叫做「人类最后的试卷」(Humanity’s Last Exam)1,是当下最火热的LLM能力检验基准之一。
这份试卷,由近1000名各领域专家设计,从最初7万多道题目,经过层层自动筛选以及严格的人工审查后,最后精选2500道。其中24%是选择题,剩下是填空/解答题。其中数学题41%,生物医药11%,计算机10%,物理9%,人文社科9%,等等:
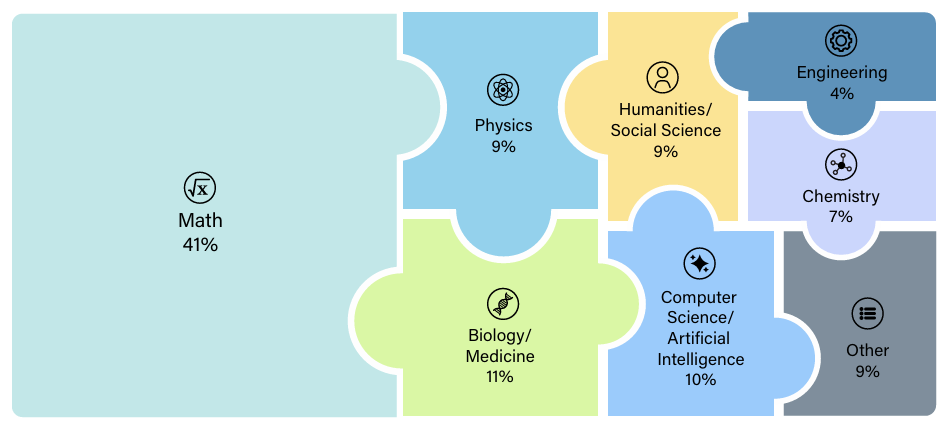
数学题长这样:

翻译不翻译,没什么区别。我本科学的是数学,也看不懂。Claude说这是个代数拓扑学和范畴论的问题,属于博士生课题。它解释了题目的大意,可需要的前置知识量太大,我一时半会还是读不懂。
那来一道至少题目本身看得懂的。生态学:
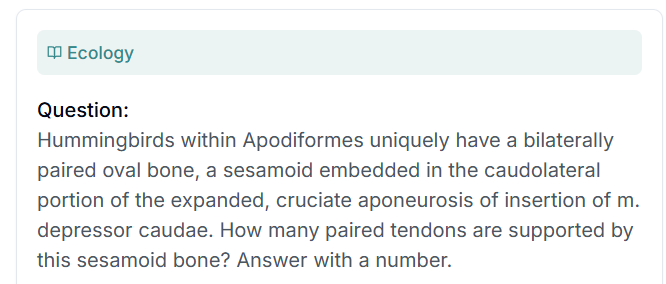
翻译一下:

考的是非常冷门且搜索不到的知识。
最后来一道语言学:

问题:我提供了来自《斯图加特希伯来文圣经》(Biblia Hebraica Stuttgartensia)《诗篇》104:7的标准化圣经希伯来语原文。您的任务是区分闭音节和开音节。请基于杰弗里·汗(Geoffrey Khan)、亚伦·D·霍恩科尔(Aaron D. Hornkohl)、金·菲利普斯(Kim Phillips)和本杰明·苏查德(Benjamin Suchard)等学者对圣经希伯来语太巴列发音传统的最新研究,识别并列出所有闭音节(以辅音音素结尾)。中世纪文献,如卡拉派转录手稿,已使现代研究者能够更好地理解圣经希伯来语太巴列传统发音的具体方面,包括示瓦音的性质和功能,以及哪些字母在音节末尾被发音为辅音。
考的是利用已有文献的方法论来在新材料上进行推断的能力。
「人类最后的试卷」最初发表时,最强大的模型还是 o3-mini(2025年1月),仅有13.4%正确率。现在官方记分牌上排名最高的是 gpt-5(2025年8月),26%正确率。非官方的话,采用多智能体架构的 grok-4-heavy 声称已达44%。
我没找到任何数据表明「单个人类」来做这2500道题的成绩,但主观上我相信不可能超过44%。就算你把数学史上最后的通才希尔伯特复活了,他也被这41%的数学相关问题卡住上界。
如果想知道问题的答案,在这里下载数据集。他们没有把明文放在网上,是为了避免文本被收录进LLM训练语料库而导致「漏题」。)
不过,至少这些题目的答案,还是「全人类」已知的。每个具体的人,还有点儿形而上的慰藉。
未解决问题(UQ)
然而,最近又出了个「未解决问题」数据集 (Unsolved Questions)2。论文作者从StackOverflow这个问答网站上精选了500道从未被用户回答过的问题。这些问题都有较高的用户关注度(views)和票选(votes),且经过LLM和人工筛选出那些「定义清晰、难度高、可解决、客观」的问题。符合这些标准的500个问题里,数学题依然占大多数。
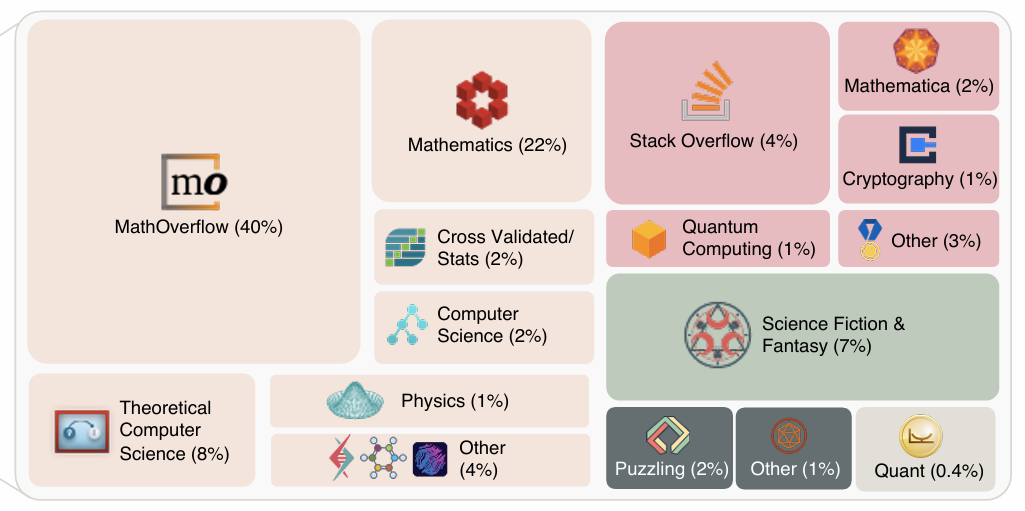
但也有很多「我小时候读过这么一个讲XXXX的科幻小说,有人知道书名吗」,「是否有历史文献记录了古印度的“石中活物”(如乌龟、蟾蜍)」,「我来给大家出个字谜哈」之类相对日常的问题。
可如果连我们自己都(还)不知道答案,那要如何判断LLM的回答是否「正确」呢?
这本身就是一个非常有意思的问题了。论文作者的解决方案是,让LLM组成一条分工明确的流水线,做逐步审核。因为一般来讲,「检验一个回答是否正确」比「给出一个正确的回答」要容易得多。
审核具体方案不详述,大致是让LLM分别检验回答对问题而言是否中肯完备、细节引用和逻辑是否有硬伤,并多次独立审核,最终需要全票/多票通过。个人认为有很多可以商榷改进的地方。例如,该方案其中一环会检测LLM的回答中是否存在细节上的逻辑错误,一旦发现,就会判定最后回答错误。这对数学题一般是可行的,但其他无需强逻辑链的回答会被误伤。
比如下面这个求科幻小说书名的例子(已翻译,原问题链接):

o3-pro对此问题的回答是:

这个回答在被论文作者发布到原问答网站后,一位人类用户认为它是「错误的」,因为第7点中提到这篇小说如果按平装本算,应该有150-180页,但Wilson Tucker的这本《The Year of the Quiet Sun》有252页。这位用户评论到:“(要是这点都错了)那我们怎么能信任(答案的)其他部分呢?”
最后,提出问题的原发帖人回复了,确认这本书就是他以前读的那本。
现在这个问题仍然在数据集中被认为是「未有回答通过正确性检验」。我特意单出这个例子,是因为这种判错的「心态」非常典型,也非常眼熟:揪住细节错误,然后爽快全盘否定。
顺带一提,包括上例,论文作者们发布到StackOverlow的所有帖子几乎都被管理员删除了,因为该网站严控AI生成内容。这也很应景当下。
阅读这些未解决问题、LLM的回答(不论「正确」与否)、LLM的验证理由、以及人类的审核意见,其实相当有趣。探索智识边界的尝试、思考、验证过程,竟以文本形式批量集中公开了。
和「人类最后的试卷」不同,这些都是人类个体自己真的想要知道答案的问题。建议大家去他们的官网上瞧瞧,特别是看看自己领域相关的问题。我印象比较深的两个:
- 已知邻接矩阵特征值绝对值,求解特征值正负号。这个是我相对熟悉的计算领域,gpt-5给出的解法是聪明且可行的,而且复杂度分析也在一定程度上暗示了原问题的计算量疑问。如果是当年还在读书时的我,或许能快速尝试一些解法。现在恐怕要先花很多时间复习知识,重新磨刀。
- 瑞典与芬兰之间最早的陆上通路是哪条。这个看似可以搜索的知识类问题,其实答案并不明显,因为提问者要求这条路是有史可查且基于「特定目的」修建的(如驿道),而不是民间自然形成的通商道路。gpt-5的回答首先确认了瑞典本土最早的皇家邮政网络于1636年成立并包括了沿海大道Kustlandsvägen,而当时还是瑞典辖下的芬兰的沿海大道Pohjanmaan rantatie在修缮升级后于1638年成为正式邮政道路。两者都延申交汇到边境线上的Torneå岛(现属芬兰,今天已填海成为半岛)。当时的Torneå夏季交通靠渡船,但冬季可走冰面(第一座桥建于1919年),连结了两边的邮政公路。所以gpt-5认为这三合一的道路组合,可以符合提问者的要求。这是从历史材料构造出符合定义条款的抽象事物的趣例。
「未解决问题」数据集的思路是:收集那些还未被人类解答的问题,通过LLM自动验证流水线来筛出最有可能的AI回答,并提交给人类专家或者原提问者做最后确认。因为论文是3周前发表的,所以现在500问里被人工验证出解答正确的,一共仅有10个,基本都是数学相关。作者认为,这既可以给LLM提供新(近似)基准,也可以帮助人类用户获得自己想要的答案。
可是,无论再怎么难回答,这些问题至少「被提出来了」,而且回答还能用语言描述。
那么,那些被AI发现,却(还)无法用语言描述的新知识,又要如何传播给人类呢?
AI教特级大师下象棋
首先,这些知识/技能已经存在了。AI早就在象棋、围棋等封闭环境中彻底战胜了人类,而且棋艺远超最强的人类选手。当今很多专业的棋手,都在学习AI的路数。但是,能下赢棋,和能讲清楚自己为什么要这样下并把「知识点」或者「技能」传授给另一位棋手,是两码事。下过棋的人会知道,很多优秀的棋招都是依赖长期训练出的「直觉」指引。而试图在事后解释这些招数的语言文字,和招数本身中蕴含的复杂性相比,显得苍白无力。
但今年初有篇论文3就用 AlphaZero (AZ) 教会了曾获国际象棋世界冠军的四位特级大师一些新的技巧。这四位特级大师是:
- Vladimir Kramnik: 2000-2007的世界冠军。积分排名历史最高:1
- Dommaraju Gukesh: 2024年的当前世界冠军。积分排名历史最高:3
- Hou Yifan(侯逸凡): 2010-2017年的女子世界冠军。积分排名历史最高:55
- Maxime Vachier-Lagrave: 2009年青少年世界冠军。积分排名历史最高:2
AZ不是个语言模型,它不讲话,只会下棋。它可以对局面棋势做出优劣判断,但这些判断暗藏在模型内部大量的黑箱数值里面,难以被人类解读。
这篇论文就是讲怎么从中抽取人类还不知晓的棋招。
大致步骤是:
- 先找到AZ仅在「下了一步好棋」(依它自己判断)时才会常常出现的数值模式
- 从这些数值模式里筛掉那些在人类棋局中也会出现的
- 从这些数值模式里筛掉AZ自己在早期训练时也会出现的
- 用剩下的数值模式去继续训练早期的AZ,然后看它能不能模仿出和最终AZ同样的这些好棋。筛掉那些无法被学习到的数值模式
上述4步之后,剩下的这些「优秀的」、「人类未知的」、「高级的」、「可学习的」数值模式,被论文作者称之为「概念」。
然后,用单个概念反向匹配对应的多个历史棋局状态。这意味着,在该局面下,AZ曾经利用过该「概念」走出一步好棋。于是,关于同一个概念的棋盘状态,可以被看做是描述该概念的实战「例子」。
下面展示了某个概念的两组不同棋局,会国象的朋友可以检视一下,据作者(一作是国象专业棋手)评论,这属于不常见的弃子夺势。
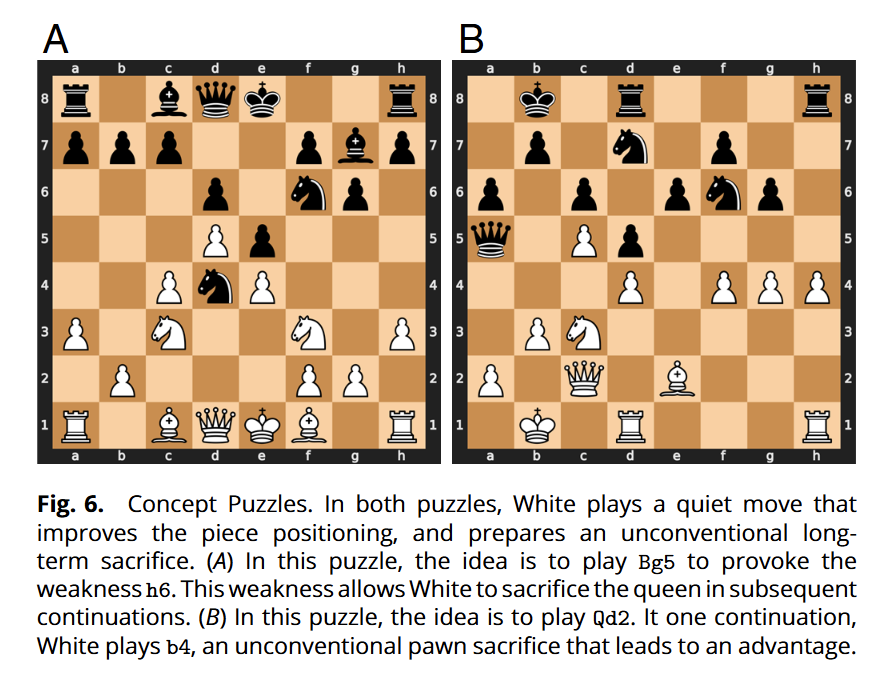
接着,让国象特级大师在若干个同一概念相关的棋局例子下,尝试走下一步棋,看他们的决定与AZ的「好棋」是否吻合。下完后,再告诉它们AZ的「好棋」是怎么下的。
如此三番,特级大师从中或许学到了些什么?论文作者再让特级大师们在同一概念相关的若干新棋局下走棋。结果发现,所有四位大师的新棋招与AZ的「好棋」吻合度都相较之前上升了。
由于AZ的棋力远胜四位大师,这个实验就证明了可以利用它的高级知识「教会」代表人类棋手能力上限的特级大师新的技术。
四位特级大师对实验过程有自己的评论。他们认为这些棋局「非常复杂——不容易想出该怎么下」。他们在分析AZ的好棋时,也认为它们是有趣的:「想法很好,也很难想到」、「聪明」、「很新」、「很有用……感觉不是很自然」、「非常有意思」。有人还事后反思自己与AZ不同的落子「太情绪化」、虽然「在技术上强势」,却在之后几步会露出破绽。
也不是所有提取出的「概念」都有用。一位特级大师发现,AZ(执黑)的某种走法属于不合实际的「主动和棋」:
“……这是一个需要理解的非常清楚且重要的主题。所以,它提议的g4这步棋,从实战角度来说是一步很重要的棋,因为你看,在这种局面下,引擎已经知道最终结果了。对引擎来说,下哪步棋都无所谓,因为它计算出这是和棋,但g4基本上是在强制和棋。g4之后黑方就没有获胜机会了,但否则我感觉如果黑方下比如说Qd2,白方要实现和棋在实战中并不……容易。对引擎来说这没问题,但实战中没人会这样下,因为g4基本上就是在提和——而其他走法黑方不承担任何风险,如果白方犯错误,还有实战获胜的机会。引擎不理解实战的概念——虽然这是和棋,但对白方来说这不是容易的和棋。g4是众多导致和棋的走法之一,但从实战角度来说是最糟糕的一步,因为它让黑方完全没有获胜机会。所以我的理解是,这不是客观上的最佳着法。从实战角度来说,这绝对是错误的走法。”
也就是说,AZ确信这局应该是和棋——如果对手也是AZ同样水平的棋手的话(AZ的训练方式就是和自己对弈,所以这个假设对它而言很合理)。它没有考虑对手水平可能更低的情况,于是不走那些会给对手带来更多局面压力的棋,而是直接逼和。但特级大师表示额外的压力会让人类级别水平的对手挣扎,从而可能出错输掉。
这篇论文很有意思。它设计了一类在海量AI黑箱数值所表征的经验中抽取蕴含「独特技巧」的范例的流程。如果存在一些新的、复杂的、又很难用平白传统语言描述的概念,那么我们至少可以精准构造/搜寻包含这些概念的实例,类似禅宗的「公案」,让人们可以「用以致学」。
AI已经在拓展人类智识的边界。这才刚刚开始。
恰如之前各个学科领域的顶尖专家,耗费毕生精力,其中一部分做出了前无古人的贡献,成为后人的坚实踏脚石。这些发现、归纳、理论、创新,铸成了我们的现代科技生活的每一方面,把一般人安全地包裹其中。这些真正的专家,离我们每个具体的人的生活很远——因为他们也有自己的生活——所以一般人只能通过教科书、科普、传媒等二手信息来接触他们集体建筑的智识地基。
可现在,拥有这些智识能力的AI,就在你触手可及的APP/API里,随时为你所用。转瞬间,人们竟智识自由了。
“The best minds of my generation are thinking about how to make people click ads. "
(我们这一代最聪明的头脑都在想着如何让人们点击广告。)
- Jeff Hammerbacher, 2011
上面这句本是某大厂员工对社会现状的无奈抱怨,到今天却成了一个震耳欲聋的实际问题:
OK,你现在有得选了,那你要让它们做些什么呢?
这是一个非常奇妙的时代岔路口。或许也是智人探险家最后的精彩旅程。
Humanity’s Last Exam: https://lastexam.ai/, 2025. ↩︎
UQ: Assessing Language Models on Unsolved Questions, https://uq.stanford.edu/, 2025 ↩︎
Schut et al, 2025. Bridging the human–AI knowledge gap through conceptdiscovery and transfer in AZ. https://www.pnas.org/doi/epdf/10.1073/pnas.2406675122 ↩︎