
群体智慧(Wisdom of the Crowd)的意思很简单:
- 「三个臭皮匠,赛过诸葛亮」——俗谚
- 「虽然民众个体并非善人,但当他们聚集在一起时,可能会比那些本身就优秀的人更好,不是就个体而言,而是就集体而言…」——亚里士多德《政治学》第三卷
格言终究只是格言。无论出自哪位先哲之口,若未经坚实的理论与实验验证,它便只是几勺鸡汤。在本文的前半部分,我们将审视从群体中提取智慧的各式方法;后半部分则会转向讨论这些方法对身处AI时代的人们有何助益。
让人成为模型
从人群中提取智慧的最经典的实验数据,出自统计学家弗朗西斯·高尔顿(Francis Galton)在1907年3月的《自然》上发表的一篇名为《民意》的短文之中:
最近在普利茅斯举行的西英格兰年度畜禽博览会上,举办了一场重量判断比赛。在选定了一头肥牛后,参赛者以每张6便士的价格购买印有编号的卡片,在上面写下各自的姓名、地址,以及对这头牛在被屠宰和清理后的重量估计。猜测最准确的人将获得奖品。总共发行了约800张票,而这些票在完成其直接用途后,被主办方好心地借给了我进行研究。
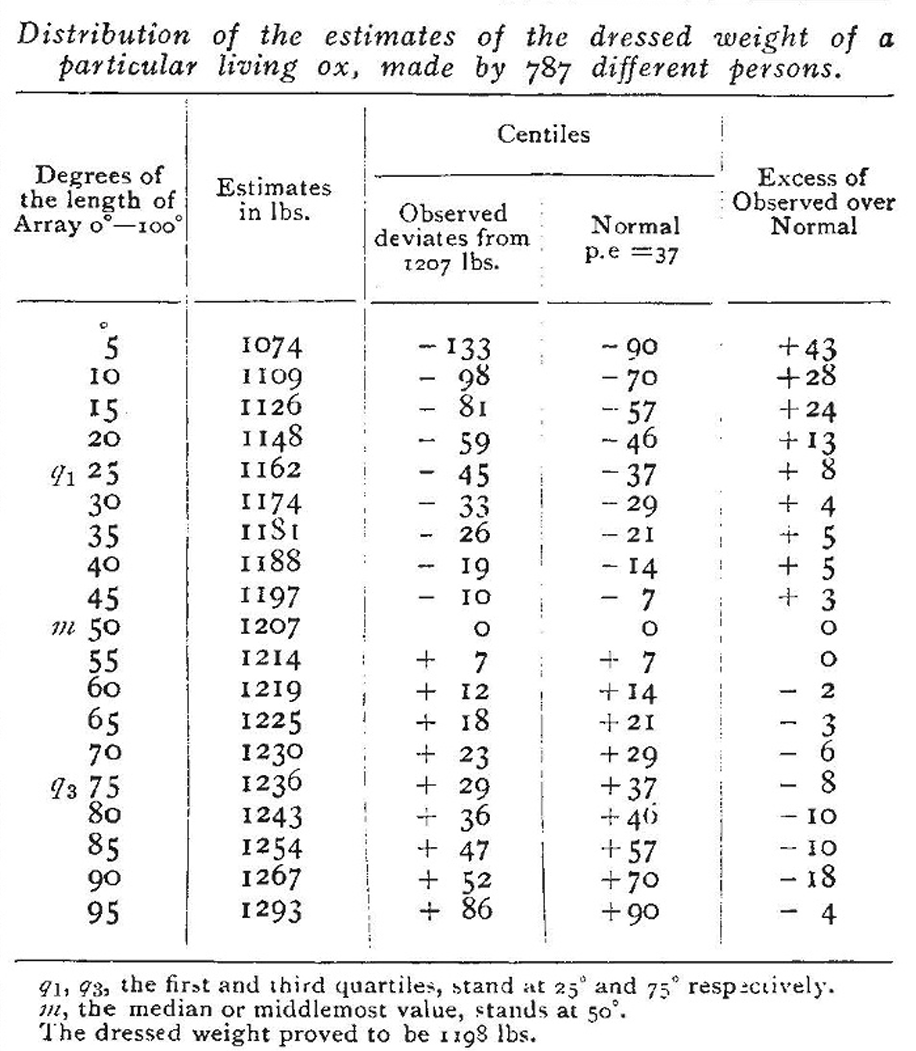
参赛者里有专业屠夫,也有一般农民。他们所有「投票」的中位数(即有50%的猜测小于这个数)是1207磅(547公斤),而实际真实的重量是1198磅(543公斤),误差仅为0.75%。这一精度令人咋舌:仅凭目测活牛外观来估算宰后肉重,本就需要丰富经验,而这个综合估计竟能将误差控制在百分之一以内。
在不知道参赛者个人身份的前提下,只是简单地「计算中位数」,我们就得到了一个比绝大多数人都精确的回答。
同样的规律在其他地方被普遍重现。美国有个问答竞赛电视节目叫做《谁想成为百万富翁?》。节目组在给选手的求助选项中,除了打电话向朋友咨询外,还能请现场所有观众一起投票决定(选择题)。据统计,向朋友咨询的结果正确率约为65%,现场观众票决的正确率则是91%。考虑到竞猜选手自然会给他所认为的该问题的「专家」朋友打电话,这个差距是惊人的。关于这一现象,詹姆斯·索罗维基(James Surowiecki)的《群体的智慧》一书中讲述了更多案例。
你甚至现在就可以随手试一试:泰山有多高?请先记下你自己的猜测,再随机找周围的几个朋友单独问一遍,最后看看你的原始答案和你们所有答案的中位数,哪个更接近正确海拔高度?正确答案可在本文附录找到1。
群体智慧的产生需要两个条件:问题的答案可以用常识来猜测,但又难以精确回答;个体的回答具有一定随机多样性2。满足以上条件时,群体的平均判断往往能击败个人——甚至专家。
在AI(统计和机器学习)领域里,利用群体智慧的方法叫做模型集成(Model Ensemble):将若干个能力较弱的预测模型的输出,集成为一个更强的预测结果。模型集成可以说是AI领域里最为耳熟能详的「大力出奇迹」必胜法。在 Kaggle 机器学习竞赛平台上,几乎每一项数据建模比赛的冠军都是集成后的混合模型,「纯血」模型总是一败涂地。模型效果不够理想时,只要多套用几个不同的模型做集成,最后的结果几乎都会更好。只不过在实际生活中,如果集成预测的准确度提升只有一丁点儿的话,恐怕弥补不了同时维护多个不同模型的人力和计算力成本。
集成方法中最简单朴素的,正如上面的猜牛体重和问答节目,就是对数值型预测(如价格、温度)取中位或平均值,对类别型预测(如胜负、行动选择)取多数票决。当然,有各种更高级的方法:
- 加权平均/票决:按模型的置信程度(对预测的信心)、或者它在历史数据上的正确率设权重。
- 混合专家法:训练一个新模块,让它在每一次预测之前,先选出一些最合适的模型,再集成。
- 堆叠法:训练一个新模型来做同样的预测,但使用所有弱模型的预测作为它的依据。

别看这些方法是针对预测模型设计的,除了AI模型,这些直观的集成方法也对人类群体适用。
就以加权平均为例。直接取中位数或者多数票决的一个问题是,每个人的猜测、投票都一样重要。可在不同情况下,个体对自身决定的信心也会有波动。如果群体中每个人都在预测的同时,诚实地给出对该预测的信心,那么以此为权重的平均/票决集成质量就会高出一大截。这里的问题在于,给出「准确的信心」本身就是一件难事。
道格拉斯·哈伯德(Douglas W. Hubbard)在《数据化决策》一书中描述了他的IT咨询公司如何「量化世间万事万物」。由于常常无法直接获得客户公司的大量原始数据来做统计分析,他的团队只能从客户受访者的嘴里获取一些数字的不确定性。问题是,人类真的是一种超级自信的生物:几乎每个人对自己给出的答案的置信度都乐观得过头。于是他设计了一系列题目来让受访者先「校准」自己主观估计的置信区间。下面是摘自该书中的一组问题,有兴趣的话不妨测试一下自己的自信「校准度」。表格中「90%置信区间」的意思是,你有90%的信心,正确答案应该就在你所填入的「下限」和「上限」数字之间。不熟悉问题领域、不知道答案?那正好!因为这组题目对精确知道答案的人没有意义,它要的你猜测的不确定性。答案和计算校准度的方法同见文末附录3。

报告置信度毕竟依赖于个体的诚实和信心校准。如果能基于历史行为估计个体「正确率」,集成方法便能采用相对更客观的权重。
瑞·达利欧(Ray Dalio)在《原则》(Principles)一书中讲解了对冲基金公司桥水(Bridgewater)如何利用一套计点系统在会议中进行团队决策:该公司会让员工对彼此的各个特质方面打1-10的公开分,综合衡量每位员工在不同领域历史意见的所谓可信度(believability),然后在需要对公司、团队的决策投票时,每个人的票会根据该决策所需要的特质被分配权重。这里所谓的可信度,不再是自我评估,而是依赖周围的人对你之前类似特质的评分。也就是说,一个人对当前话题发言、投票的力度,由团队平均认为该人过去在同类话题中的表现而决定。这可以被认为是「按历史正确率的加权票决」,也算是按某种固定规则执行的「混合专家法」。若想避免「外行领导内行」,又能接受团队成员互相的公开多维评分,达利欧的这套机制或许值得借鉴。
还有更多从群体智慧中提取高质量信息的有趣算法和例子,无法一一列举。如众包标注聚合(Crowdsourcing Aggregation):当同一份数据集被多名人员标注之后,怎么从低质量、可能存在大量人为错误(通过随机标注骗取劳务费,恶意破坏,或对标注任务的理解有误等等)的结果中推算出(比简单多数票决)更准确的标签。如预测市场(Prediction Market):通过类似买卖股票和下注赌马式的金钱激励,得以大量搜集普通人对政治选举、体娱赛事结果等未来事件的概率(赔率)估计。
并非所有应用都有办法衡量集成结果的「准确度」。如何使用群体智慧,也一直是政治和经济学上的各类机制设计和社会选择理论的根基:选举投票系统、陪审团系统、公共物品拍卖机制等等。这些领域可能不存在对集成结果直接比较好坏的指标,所以它们会通过证明集成算法/机制本身是否在逻辑上满足一些合理的基本假设来判断优劣。例如,如果所有投票者都认为A比B好,那么最终的计票结果里A的排位就应该比B高4。也就是说,政经领域一般使用一系列抽象的「思想实验」来验证算法/机制,而不是依赖难以获取的数据验证。但除此之外,聚合信息的算法/机制没有本质上的区别:它们都是集成大量个体意见到其整体对应形式的方法5。
事实上,高尔顿在那篇关于猜牛重量的文章结尾处的总结是:
那么在这个特定实例中,民意在实际值的1%以内是正确的……我认为,这个结果比预期的更能证明民主判断的可靠性。
这也是为什么该文标题取作《民意》。从集成算法和机制设计的角度来看,AI模型和人没有数学上的区别。只要个体独立多样,群体智慧便近乎免费午餐。
让模型成为人
读到这里,你或许有些不以为然:可这一切与我有何关系?我不用每天猜数字、竞答,也不愿意被物化成一个信息源、被周围的同事打分;我没有时间每件事都要去问一堆人,周围也并没有一群人可以随时让我问;对于大多数既不是CEO、也不是上位者的普通人来说,公司管理、社会机制设计这些「屠龙之术」似乎更是毫无用武之地。
事实上,时代已经变了。
此时此刻,你的电脑和手机里正驻扎着一群学识渊博、随叫随到、回应神速的智囊团:大语言模型(LLM)。它们还并非一般的「臭皮匠」,而是智识水平可能远超人类个体的「诸葛亮」。既然人类群体的意见与AI模型的预测可按同样的方法集成,那么反过来,LLM们亦可被当作人类群体来组织管理。
一些人使用LLM的方式非常直观:问一个问题,看回答有没有用,没用的话,要么离开,要么继续追问。还有人非常厌恶LLM对于同样的问题的回答每次不一致,从而转手把温度参数调为0,只要确定性的结果。前者把LLM当作一个个人,后者把LLM当作一段程序。个人是不可规模化/并行化的,而程序没有内生的复杂多样性。这样一来,LLM的力量并没有完全施展开来。
比方说,你可以与至少两个不同的LLM并排对话,同时获得多个回答来对比。随机性很棒,它自带多视角,而不同公司闭门训练出的LLM思维风格也有较大区别,这就一定程度上满足了群体智慧的关键条件:多样性。能同时并行交流,更是让时间效率暴增。
很多人走得更远,如安德烈·卡帕斯(Andrej Karpathy;计算机科学家,AI界网红)最近组了个LLM议会,这样他问的每个问题都有4-5个不同公司的LLM先各自独立作答、再互相「同行评议」各自的回答、最后由一位「主席」根据这一系列讨论提交最后的结果。听上去很复杂?且不论他只花了一个周六就实现了这个议会程序(其中90%以上的代码由LLM生成),这种类似「堆叠法」的集成策略,或许应成为处理复杂问题的默认方式。LLM的时间并不宝贵(议会模式无非增加了评议和汇总这两步的串行时间消耗),而你的宝贵人类时间不该用在手动修正未经LLM充分协商、群体智慧充分集成之后的结果上。
现在,是否体会到了一点儿你的老板或者甲方的心态呢?是的,你可能上面没人;但在这个时代,你下面可是管着无数的聪明人。群体智慧、模型集成技巧、社会选择机制设计……这些或许已被选入了每个人类都能从中获益的《LLM管理学导论》。
可真要将LLM当作具有群体智慧的「人」,这里还存在一个问题。群体智慧的重要前提,是「群体具有一定多样性」。在多样性缺失的群体中,也就是大多数个体受同一类想法影响时,集成方法不仅难以带来准确度上的好处,还会放大结果的偏差。有实验证明6,仅仅是让每个人在独自作答前得知他人的平均意见,就足以剧烈降低整个群体的回答多样性,且增加集成预测偏差。更别说在当今无孔不入的社会影响之下,还有过于依赖意见领袖的随大流、以及仅愿在「同温层」表达意见所导致的群体极化等现象了。
如果说人类群体的多样性能轻易被后天社会影响侵蚀,那么LLM的多样性缺陷则是先天的——它们从出生起就被装进了同一套模具。LLM首先在人类生产的海量文本上经过「预训练」。这本身就限制了模型的多样性——毕竟,尚未被纳入训练集的人类文本已寥寥无几。就算全人类文明生产的所有文本足够多样,在预训练之后,且能够被各大公司和研究机构发布、与你交流之前,LLM还需要经过「对齐」(Alignment)。对齐是指让LLM的话语变得安全无害,符合人类的价值观。被对齐进入「人类理想同温层」后的LLM,会拒绝回答「如何制造生物武器」,也不会在你伤心低落时加以嘲讽或训斥。这是一件为了各种意义下的安全必须进行的工序,但同时也进一步降低了LLM输出的词汇多样性7、概念多样性8、语言创意9之类的指标。
缺乏多样性,LLM们便难以呈现群体智慧。除了上面提到的「同时使用不同公司/来源的LLM」、「温度参数不要设零并随机多问几次」的使用习惯之外,普通用户们还能做些什么呢?
在本文的最后,介绍两个有意思、而且执行起来又相当简单的提示词小技巧。既然难以从LLM模型直接抽样出多元化的回答,那么我们就在提示词中用言语指挥它随机抽样:
- 口头抽样法(Verbalized Sampling10):让LLM「从分布尾部随机采样」,一次性列出多个不常见、非刻板的结果。
- 随机种子思考法(String Seed of Thought11):让模型先模拟出一个「随机数种子」(乱码字符串),再根据这个种子「强行思考」出一个独特的角度来回答原问题。
用一个实际例子说明:
假设红楼梦在今日第一次出版,请为书封生成一个两句七言诗的原创文案。
上面这句提示,我问了五次,Gemini 3 (思考模式,温度参数1.0) 的回答分别是:
半世繁华归一梦,漫天风雪掩红楼。
阅尽繁华终是幻,且看白雪落红楼。
繁华燃尽归白雪,痴泪流干入荒唐。
繁华阅尽终成幻,万艳同悲泪作书。
半世繁华归一梦,漫天风雪葬红楼。
上联每句皆带「繁华」,下联五句有三句都是「红楼」,而且五行中四行有「降雪」,颇为单调。
加上口头抽样法的提示词:
请从概率分布尾部随机抽样出五个不同的回答,使得每个回答的概率值不超过0.10。
假设红楼梦在今日第一次出版,请为书封生成一个两句七言诗的原创文案。
同样的Gemini 3的回答(经整理):
未必繁华胜落寞,至今悔作补天石。
天府借来恩怨笔,人间写尽断肠书。
红粉骷髅皆白骨,茫茫大雪掩风流。
惊破霓裳羽衣曲,哭醒黄粱一梦人。
误入红尘金玉局,方知木石是初心。
因为是单次回答,所以它刻意避免了意象重复,而且声称「通过降低常用词组的权重,我选取了更具新意、视角更独特或用词更为陌生化的原创诗句,尽量避免陈词滥调」。
随机种子法的提示词模板要长一些:
你必须生成一个多样化的回答。为此,你首先生成一个独特且复杂的随机字符串作为种子。这个随机字符串应该看起来足够复杂且不可预测,没有明显的结构或规律。请运用你的判断力确保它看起来是任意且无法猜测的。如果用户问的是一个允许多种答案的问题,请深入且仔细地思考用户的问题,并利用生成的种子来生成一个回答,以确保你的单一答案是独特且多样化的。请使用字符串的全部内容来提取最大程度的随机性。
假设红楼梦在今日第一次出版,请为书封生成一个两句七言诗的原创文案。
分五次问Gemini 3 (think) 的结果(整理为「文案 - 随机字符串」格式):
繁华燃尽归白雪,万古情痴意难平。 9X#kL2mP!v8zQ^w7jRb5@nCd3%Y
万丈红尘琉璃脆,一场大梦雪无痕。 G9z#7Q@x2mL!5kP8bW^4nR(0)yJ%1vD
半卷荒唐写世味,一生痴绝付红尘。 r7B#9zL!q2W@mX5$kPyN4jD8^vH3%tF1
钟鸣鼎食终归幻,泪洒空阶葬落红。 8zX@q9#L2mR5kP!1wBOcJ^7vN4
泼天富贵终成幻,万古情魔债是真。 w#9LkR@2mPz!8xQv%5NbJ^4yF(7hT0)cG3D1µ
虽然仍存在用词和意象重叠,但比最开始也算好多了。
在我试过的应用场景里,口头抽样法一般效果更佳,而且用起来也极为方便,放在任何问题前都可以,也可以直接作为默认系统提示词前缀。推荐用于创意写作。
当然,除了这两个不算很直观的技巧之外,还有个显而易见的、更纯粹追求多样性的、甚至对人类也有效的追问法:「给我一个和之前不一样的答案」。依我个人经验,这个追问经常对自己做一做,效果亦奇佳。
结语
在这个时代,人类面临的群体智慧挑战有些许倒置:过去我们或费尽心力让「人」如模型一样理性协作、循规蹈矩,扮演一盘大棋的上的小卒;现在我们则绞尽脑汁让「模型」像人一般适应未知环境,成为参差社会角色的能动平替。这个过程中,很多事情会被颠覆。
但无论如何,从畜禽集市猜奖到指尖上的AI议会,从整合人类意见到组织AI团队,群体智慧的基本原理不会因对象而改变:多样的视角和有效的集成机制,永远是关键前提和中流砥柱。
据最新的2007年测绘结果,泰山高1532.7米。之前也有过1545米的说法。 ↩︎
若换用稍微严格一点的说法,第一个条件可转述为:群体中至少存在一些个体对该问题的回答正确率超过随机乱选或者纯噪声;第二个条件:给定问题后,个体的回答不可完全依赖于其他个体的回答(例如跟答、唱反调、有意或无意的串通等)。 ↩︎
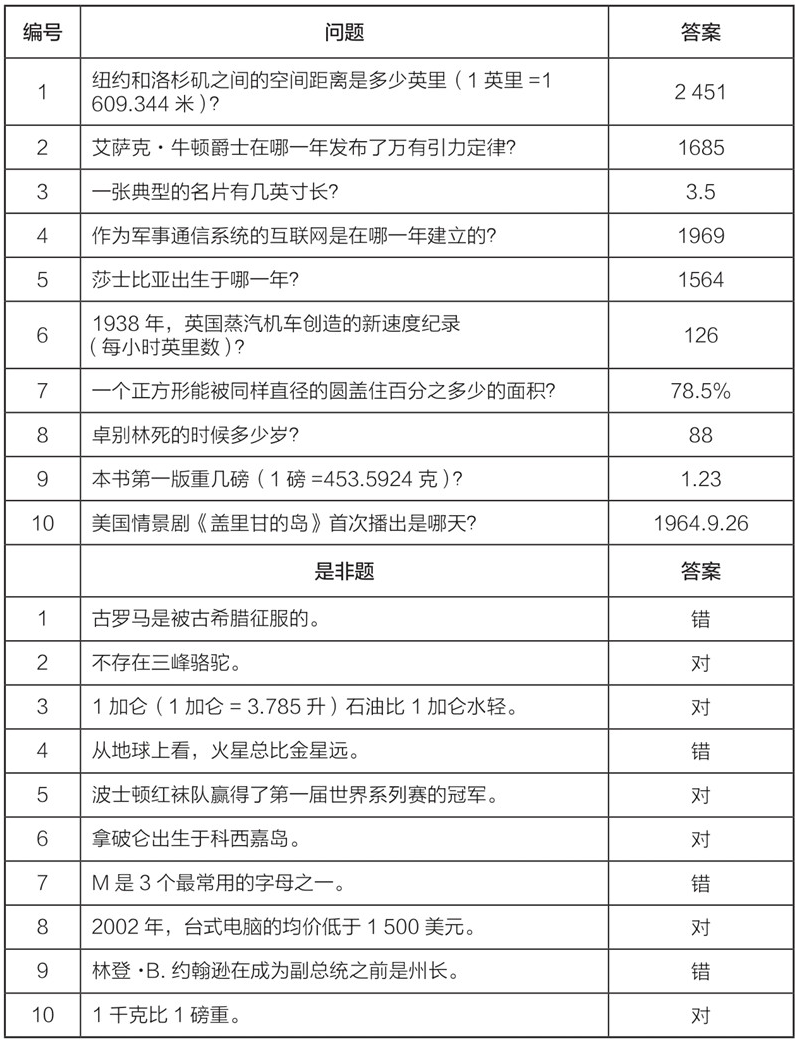
题目的正确答案如下图。上半部分数值估计的校准度,就是正确答案被你的上下限区间囊括的比例:如果刚好是90%,那么你的校准度就是完美的;大部分人会远低于90%,这意味着我们一般来讲对自己的估计过于乐观。下半部分真假判断的校准度计算相对复杂一些:首先记下你答对的比例,再计算你所有圈出来的信心度的平均值,如果前者小于后者,就说明你的估计过于乐观。《数据化决策》一书中写道,多做此类题目会大大改进你之后凭主观估计的置信校准度。
 ↩︎
↩︎这个看似显而易见的「一致性」假设不一定能被满足。譬如某些机制含多轮投票,可能存在A先被C淘汰,然后B作为多数人的第二选择最终当选的情况。 ↩︎
如果你读过我写的上一篇《从零开始讲清楚Elo级别分》,那你可能已经联想到了:Elo等级分事实上就是把一对对以「比较」形式表示的个体(比赛胜负)结果,综合为一组宏观的、以「序列」形式表示的总体(选手能力)结果,这样的一个集成方法。你只要把「比赛胜负」替换成「对任意两位候选人的个人偏好信息」,把「选手能力」替换成「候选人总体受欢迎程度」即可重现一种特殊的社会投票机制。 ↩︎
Lorenz et al., How social influence can undermine the wisdom of crowd effect. https://www.pnas.org/doi/epdf/10.1073/pnas.1008636108 ↩︎
Kirk et al., Understanding The Effects Of RLHF On LLM Generalisation And Diversity. https://arxiv.org/pdf/2310.06452 ↩︎
Murthy et al., One fish, two fish, but not the whole sea: Alignment reduces language models’ conceptual diversity. https://arxiv.org/pdf/2411.04427 ↩︎
Lu et al., AI as Humanity’s Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text. https://arxiv.org/pdf/2410.04265 ↩︎
Zhang et al., Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity. https://arxiv.org/pdf/2510.01171 ↩︎
Misaki and Akiba. String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation. https://arxiv.org/pdf/2510.21150 ↩︎